Quick Summary
The best web scraping APIs in 2026 handle JavaScript rendering, proxy rotation, CAPTCHA solving, and rate limit management at scale. The right choice depends on your data volume, target sites, and whether you need raw HTML, structured JSON, or AI-ready datasets. Managed enterprise APIs eliminate infrastructure overhead entirely delivering clean data with a single API call.
Key Takeaways
- Web scraping APIs abstract away infrastructure — proxies, headless browsers, CAPTCHA solving, and IP rotation are handled server-side.
- JavaScript rendering is essential for SPAs and dynamically loaded content; not all APIs include it by default.
- Enterprise-grade APIs offer dedicated IP pools, SLA guarantees, and compliance frameworks that self-hosted scrapers cannot match.
- Anti-bot protection bypass is now the primary differentiator between basic and advanced scraping APIs.
- Structured data extraction (JSON output) is becoming standard, reducing post-processing overhead significantly.
- AI training data pipelines increasingly depend on large-scale, clean web data — making API selection a strategic decision.
- Pricing models vary widely: per-request, per-GB, and flat-subscription models each have different unit economics at scale.
What Is a Web Scraping API?
A web scraping API is a cloud-hosted service that accepts URLs as input and returns web content — HTML, JSON, or structured data — as output, while managing the entire extraction infrastructure on your behalf.
Unlike locally installed scrapers, APIs handle IP rotation, browser emulation, session management, and anti-detection automatically. You send an HTTP request; you receive usable data.
Definition: A web scraping API is a managed remote service that extracts web content from target URLs at scale, abstracting away proxy management, browser rendering, and anti-bot bypass so developers can retrieve structured data with a single API call.
How Does a Web Scraping API Work?
The typical request lifecycle has five stages:
- Request dispatch — Your application sends an HTTP GET or POST to the API endpoint with the target URL, JavaScript rendering flag, geolocation settings, and output format.
- Proxy routing — The API selects an appropriate IP address from its residential, mobile, or datacenter pool based on the target domain and geo-targeting configuration.
- Browser or HTTP fetch — A headless Chromium instance (or plain HTTP client) fetches the page, executing JavaScript if required.
- Anti-bot handling — CAPTCHA solving, TLS fingerprint randomization, user-agent rotation, and behavioral mimicry are applied automatically.
- Data delivery — The rendered content is parsed, cleaned, and returned in the requested format: HTML, Markdown, JSON, or a custom extraction schema.
Why Use a Web Scraping API Instead of Building Your Own?
Building a production-grade scraper in 2026 is not a simple Python script. Modern anti-bot systems — Cloudflare, Akamai Bot Manager, DataDome, PerimeterX — detect scrapers based on behavioral signals, TLS handshake fingerprints, browser canvas hashes, and mouse movement patterns.
Maintaining a self-hosted scraper that reliably bypasses these protections requires ongoing engineering: residential proxy pools, headless browser management, CAPTCHA integration, and fingerprint libraries. This investment is rarely justified unless web data is a core product capability.
Self-Hosted vs. API-Based Scraping
| Dimension | Self-Hosted Scraper | Web Scraping API |
|---|---|---|
| Infrastructure cost | High (proxies, browsers, servers) | Included in API pricing |
| Anti-bot maintenance | Ongoing engineering effort | Managed by provider |
| JavaScript rendering | Manual Puppeteer/Playwright setup | Built-in, configurable |
| CAPTCHA handling | Requires third-party integration | Automatic |
| Scalability | Manual horizontal scaling | Auto-scaled on demand |
| Time to first data | Days to weeks | Minutes |
| Compliance & SLA | Self-managed | Provider SLA + compliance docs |
| Structured output | Custom parsing required | Often built-in (JSON schema) |
What Features Should the Best Web Scraping APIs Have?
Not all APIs are equal. These capabilities separate entry-level tools from production-ready platforms.
1. JavaScript Rendering
Single-page applications built with React, Vue, or Angular load content dynamically after the initial HTML response. An API without headless browser support returns empty or incomplete pages for these sites.
Look for: Configurable wait conditions (wait for selector, network idle), screenshot capture, and interaction support (scroll, click).
2. Anti-Bot Protection Bypass
Modern bot detection checks TLS handshake fingerprints (JA3/JA4), HTTP/2 header order, browser canvas signatures, and behavioral timing. The best APIs emulate real browsers at every layer — including TCP/IP stack characteristics.
Look for: Cloudflare bypass, Akamai bypass, DataDome handling, and automatic CAPTCHA resolution.
3. Proxy Network Quality
Residential and mobile proxies have significantly lower block rates than datacenter IPs on commercial websites. The size, geographic diversity, and rotation strategy of the proxy pool directly determines success rates.
4. Geolocation Targeting
Prices, search results, and product availability vary by geography. For e-commerce intelligence, routing requests through specific countries or cities is essential.
5. Rate Limit Handling and Retry Logic
Production workloads hit rate limits. The API should handle exponential back-off, retry on 429/503 responses, and distribute volume intelligently — without requiring custom retry logic in your application.
6. Structured Data Extraction
HTML-to-JSON parsing, CSS/XPath selector support, and AI-based extraction schemas eliminate downstream transformation work. Advanced APIs return clean, schema-conforming JSON from unstructured pages.
7. Compliance and Data Governance
For enterprise deployments, GDPR compliance, data residency options, audit logs, and contractual SLAs are non-negotiable.
Key Criteria for Choosing the Best Web Scraping API
| Criterion | Why It Matters | What to Look For |
|---|---|---|
| Success Rate | Determines actual data yield vs. API spend | > 95% on major e-commerce/social sites |
| JavaScript Rendering | Required for SPA and dynamic content | Chromium-based, configurable wait conditions |
| Anti-Bot Bypass | Determines viability on protected sites | Cloudflare, DataDome, Akamai support |
| Proxy Network | IP quality drives block rates | Residential + mobile IPs, geo-targeting |
| Structured Output | Reduces post-processing cost | JSON schema, CSS/XPath selectors, AI extraction |
| Rate Limiting | Prevents workflow failures at scale | Auto-retry, back-off, concurrency visibility |
| Pricing Model | Unit economics at production scale | Per-request vs. per-GB vs. subscription |
| SLA & Uptime | Reliability for production pipelines | 99.9%+ uptime, dedicated support tier |
| Compliance | Required for enterprise use | GDPR docs, data residency, audit logs |
| Developer Experience | Integration speed and maintenance | SDKs, clear docs, webhook/async support |
Web Scraping API Use Cases by Industry
E-Commerce and Retail Intelligence
Competitor price monitoring is among the most common enterprise scraping use cases. APIs must handle large product catalogs, frequent layout changes, and login-gated pricing. Structured JSON output with schema validation is critical at this scale.
- Real-time price intelligence across thousands of SKUs
- Stock availability tracking and out-of-stock alerts
- Product attribute and review aggregation
- MAP (Minimum Advertised Price) compliance monitoring
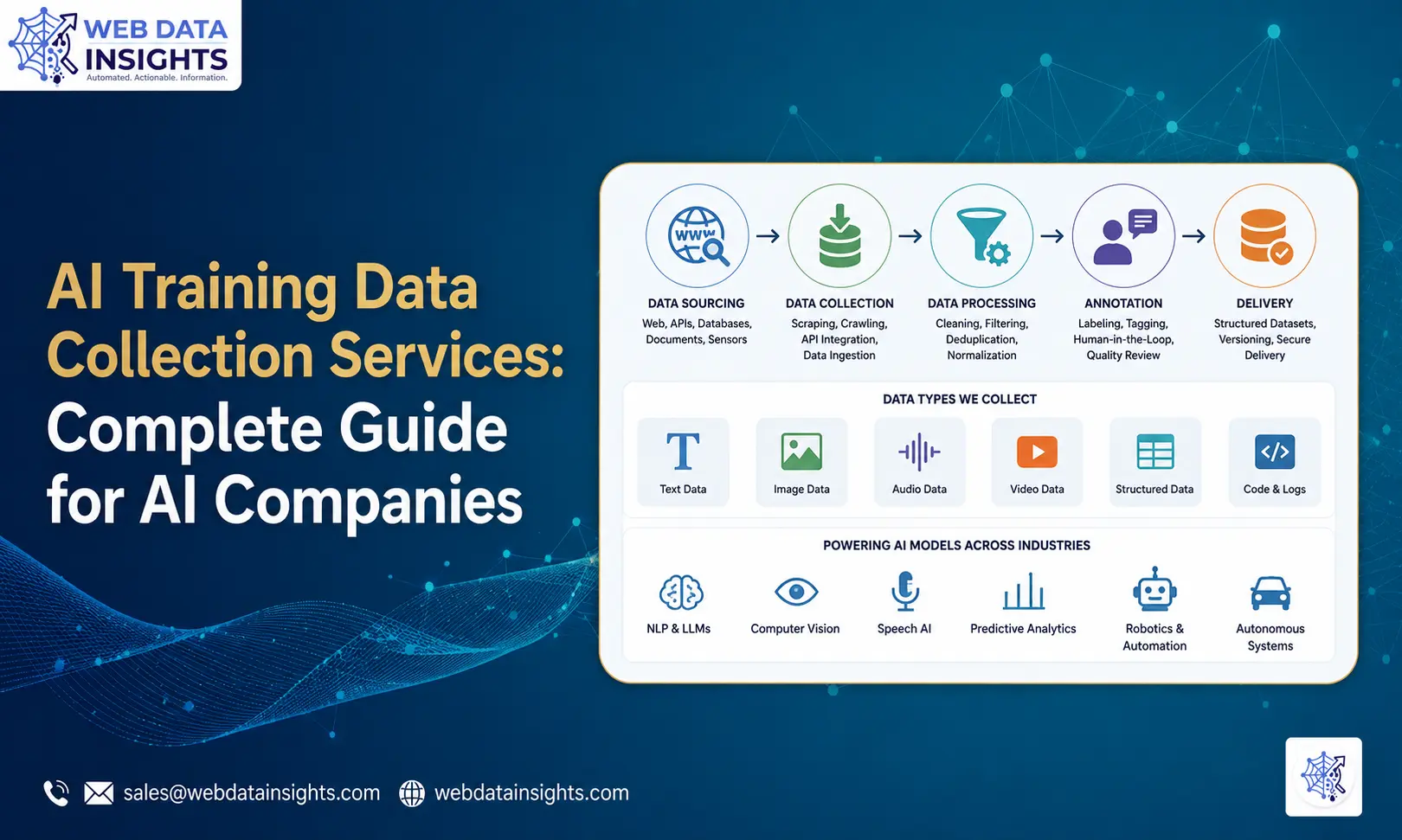
AI Training Data Collection
Large language models require clean, diverse, large-scale web corpora. Purpose-built AI training data collection services use scraping APIs as the core extraction layer, transforming raw web content into structured datasets for fine-tuning, RLHF annotation, and domain-specific pre-training.
- Domain-specific corpus construction for fine-tuning
- Multimodal data collection (text + images + structured data)
- Deduplication and quality filtering pipelines
Financial Data and Market Intelligence
Hedge funds, quant traders, and fintech platforms collect earnings data, analyst sentiment, SEC filings, and alternative data. Latency, reliability, and structured output are paramount here.
- Earnings call transcript collection
- News sentiment aggregation across thousands of sources
- Alternative data: shipping signals, job postings, pricing indices
Lead Generation and B2B Data
Sales and marketing teams extract contact details, company information, and firmographic data from directories and industry databases. GDPR compliance and data freshness dominate selection criteria.
Real Estate and Travel Data
Aggregators collect listing prices, availability, and reviews. JavaScript-heavy sites and frequent layout changes make API-based scraping significantly more maintainable than custom scrapers.
How to Evaluate Web Scraping APIs: A Practical 5-Step Framework
Step 1: Define Your Data Requirements
- What format do you need? (HTML, JSON, Markdown, CSV)
- Which target sites? Are they JavaScript-heavy or anti-bot protected?
- What volume? (requests/day, peak concurrency)
- What latency is acceptable for your use case?
Step 2: Test on Representative Target URLs
Free trial credits are standard across major providers. Test on your actual target domains — not demo sites. Key metrics to capture:
- Success rate (2xx responses as a percentage of total requests)
- Average response latency (ms)
- Data completeness (is dynamically loaded content present?)
- Output format accuracy (does JSON schema match expectations?)
Step 3: Stress-Test Rate Limits and Concurrency
Send concurrent requests at your anticipated peak volume. Observe how the API handles back-pressure: does it queue gracefully, return clear error codes, and retry automatically?
Step 4: Evaluate Pricing at Production Scale
Calculate the fully-loaded cost at your expected monthly volume. Per-request pricing with JavaScript rendering enabled typically costs 5–10x more than plain HTTP requests — account for this in projections.
Step 5: Review SLA and Support Terms
For production pipelines, confirm uptime SLA, incident response time, and whether dedicated support is available at your plan tier. Pipeline downtime has direct business cost.
Common Mistakes When Choosing Web Scraping APIs
Ignoring JavaScript Rendering Requirements
Teams frequently underestimate how many target pages load content dynamically. Always test with a headless browser enabled before assuming plain HTTP requests suffice.
Underestimating Proxy Quality Impact
Datacenter IPs are blocked at significantly higher rates on e-commerce and social platforms. If your success rate is below 85% on critical targets, proxy pool quality is likely the bottleneck — not your parsing logic.
Not Accounting for Retry Costs
Retries count as API calls. If initial success rate is 80%, you will consume approximately 25% more credits than expected to achieve full data coverage. Factor retry overhead into cost modeling.
Treating All APIs as Compliant by Default
Many scraping APIs operate in legally ambiguous territory. For enterprise deployments, verify that your provider offers data processing agreements (DPAs), does not retain personally identifiable information, and can provide GDPR/CCPA compliance documentation.
Over-Engineering Before Validating the Use Case
Start with a managed API, validate data quality and business value, then evaluate whether custom infrastructure is justified. Industry estimates suggest fewer than 20% of scraping projects reach the volume where self-hosted infrastructure becomes economically competitive.
Enterprise Web Scraping APIs: What’s Different?
Enterprise deployments have requirements that go beyond developer-tier plans. Purpose-built enterprise web scraping API services typically provide dedicated infrastructure, custom SLAs, compliance documentation, and volume pricing unavailable on self-serve tiers.
Dedicated Infrastructure
Shared proxy pools create noisy-neighbor problems at high volume. Enterprise tiers allocate dedicated IP ranges and compute resources, ensuring consistent performance regardless of other customers’ usage.
Custom Extraction Schemas
Rather than returning raw HTML, enterprise APIs extract data into pre-agreed JSON schemas — normalized, validated, and ready for direct ingestion into data warehouses or operational databases.
Compliance and Legal Coverage
GDPR, CCPA, and industry-specific data regulations require documented compliance. Enterprise contracts include data processing agreements, data residency options, and audit log access.
Dedicated Solution Engineering
Enterprise contracts include onboarding support to design optimal scraping architectures, handle site-specific extraction challenges, and monitor pipeline health proactively.
Web Scraping API vs. Managed Web Data Services: When to Use Each
| Scenario | Best Approach | Reasoning |
|---|---|---|
| Need raw HTML, full parsing control | Scraping API | Maximum flexibility, custom extraction logic |
| Need structured JSON from specific sites | Managed data service | Pre-built extractors, maintained schemas |
| One-time data collection project | Scraping API with trial credits | Low commitment, fast setup |
| Ongoing production data pipeline | Enterprise API or managed service | SLA, reliability, dedicated support |
| AI training corpus at petabyte scale | Managed AI data service | Infrastructure and compliance at scale |
| Internal BI or price monitoring | Scraping API with structured output | Balance of control and simplicity |
| Legal/compliance-sensitive data | Enterprise service with DPA | Documentation and accountability |
For teams building continuous pipelines, professional web scraping services remove operational burden entirely — delivering clean structured data on a defined schedule without requiring any API integration work.
Future Trends in Web Scraping APIs (2026 and Beyond)
AI-Native Extraction
LLM-based extraction models are replacing CSS/XPath selectors. Instead of maintaining brittle selector sets that break on layout changes, AI models understand page semantics and extract correct data even when HTML structure changes significantly. Industry estimates suggest AI-based extraction reduces selector maintenance effort by 60–70% compared to traditional approaches, at the cost of higher per-request latency.
Real-Time Data Streaming
WebSocket-based APIs and event-driven architectures are replacing batch polling for use cases requiring sub-minute data freshness. Financial data, inventory monitoring, and news aggregation are primary drivers.
Browser Automation APIs
The boundary between scraping APIs and browser automation platforms is dissolving. Modern APIs increasingly expose programmable browser sessions — enabling multi-step workflows (login, navigate, interact, extract) through a single API interface.
Anti-Bot Arms Race
Bot detection continues advancing: behavioral biometrics, device fingerprinting, and ML-based anomaly detection are now standard on major platforms. Scraping API providers are investing in browser emulation fidelity — GPU-based rendering, realistic mouse movement simulation, and TLS fingerprint randomization.
Data Compliance as a Standard Feature
GDPR enforcement and emerging AI data regulations (EU AI Act, US state-level privacy laws) are making compliance documentation a differentiating feature. Expect automated robots.txt compliance checking and structured data lineage tracking to become standard API capabilities.
Expert Tips for Getting the Most from Web Scraping APIs
Tip 1: Test on your worst-case target first. Run your evaluation against the most anti-bot-protected site you need to scrape, not the easiest. Success on a static HTML page tells you nothing about production viability.
Tip 2: Enable structured output from day one. Even if you only need raw HTML initially, selecting an API with JSON extraction capability means you can add schema-based extraction later without switching providers.
Tip 3: Monitor success rates continuously, not just at setup. Anti-bot systems update frequently. A 95% success rate at onboarding can degrade to 70% within weeks if the provider doesn’t maintain its bypass infrastructure.
Tip 4: Separate your scraping budget from your compute budget. API credit costs and downstream compute costs (parsing, storage, processing) have different scaling curves. Model them independently before selecting a pricing tier.
Tip 5: Use geolocation testing to validate pricing data. If you’re collecting competitor prices, test with geo-targeted requests to the relevant market regions — prices shown to foreign IPs are often inaccurate.
How WebDataInsights Approaches Web Data Extraction at Scale
WebDataInsights provides enterprise-grade web data extraction built for production reliability. Rather than exposing raw API credits, the platform delivers structured, validated data pipelines — handling JavaScript rendering, anti-bot bypass, proxy management, and schema normalization end to end.
For organizations requiring AI data scraping services — including clean, deduplicated corpora for LLM fine-tuning and RLHF annotation — the platform includes preprocessing pipelines designed specifically for AI training workflows.
Key capabilities include dedicated IP infrastructure, custom extraction schema design, GDPR-compliant data handling, and white-glove onboarding for enterprise data engineering teams.
Frequently Asked Questions
What is the best web scraping API for e-commerce price monitoring?
The best API for e-commerce price monitoring combines residential proxy routing (to avoid IP bans on major retail sites), JavaScript rendering (for SPAs), and structured JSON output with a product data schema. Prioritize success rates above 95% on your specific target domains and verify geo-targeted pricing support before committing.
How do web scraping APIs handle JavaScript-rendered pages?
APIs with JavaScript rendering support route requests through a headless Chromium browser, which executes JavaScript, waits for the DOM to fully load, and returns the rendered HTML. Configurable wait conditions — wait for selector, network idle — allow precise control over when the snapshot is captured.
Are web scraping APIs legal to use?
Scraping publicly accessible data is generally considered legal in most jurisdictions, supported by the hiQ v. LinkedIn ruling (9th Circuit, 2022). However, terms of service violations, collection of personal data without consent, and bypassing technical access controls introduce legal risk. Always review the target site’s robots.txt and terms of service, and consult legal counsel for regulated industries.
What is the difference between a scraping API and a proxy service?
A proxy service routes your HTTP requests through different IP addresses but leaves browser emulation, retry logic, and parsing to your application. A scraping API provides end-to-end extraction — proxy routing, JavaScript rendering, anti-bot bypass, CAPTCHA solving, and often structured output — requiring only a URL as input.
How do I choose between per-request and subscription pricing?
Per-request pricing is cost-effective for low or unpredictable volumes. Subscription pricing offers better unit economics at consistent, high volumes — typically above 500,000–1M requests per month. Always calculate the fully-loaded cost with JavaScript rendering enabled before comparing models.
Can web scraping APIs bypass Cloudflare protection?
Leading enterprise-grade APIs include Cloudflare bypass capabilities that emulate real browsers at the TLS fingerprint, HTTP/2 header, and behavioral level. Basic scraping APIs typically cannot bypass Cloudflare’s managed challenge or turnstile systems. Test on your specific targets before selecting a provider.
What is structured data extraction in scraping APIs?
Structured data extraction converts unstructured HTML into machine-readable JSON conforming to a predefined schema. Instead of returning raw HTML for your application to parse, the API extracts specific fields — product name, price, availability, review count — directly, reducing downstream transformation work significantly.
How do scraping APIs handle rate limits on target websites?
Production-grade APIs manage rate limits automatically through adaptive request pacing, exponential back-off on 429/503 responses, IP rotation to distribute load, and smart retry queues. Some providers offer configurable concurrency caps and per-domain rate limit profiles.
What is the role of web scraping APIs in AI data pipelines?
Scraping APIs are the extraction layer in AI data pipelines — retrieving raw web content at scale. Downstream processing (deduplication, language filtering, quality scoring, tokenization) is handled by separate pipeline components. The API’s reliability, structured output quality, and throughput capacity directly determine overall pipeline efficiency.
When should a business use a managed web data service instead of a scraping API?
When the business requirement is clean, ready-to-use data — not a scraping tool — a managed service is more appropriate. This is particularly true for ongoing production pipelines, regulated industries requiring compliance documentation, and large-scale AI training data collection where managing API credits and parsing logic is not a core competency.
Conclusion
Choosing the right web scraping API in 2026 is less about finding the most feature-rich tool and more about matching capabilities to your specific data requirements, target sites, and operational constraints.
For teams needing maximum control and custom parsing, a developer-tier API with JavaScript rendering and residential proxies covers most use cases. For production data pipelines at scale — especially those feeding AI systems, pricing engines, or financial analytics platforms — enterprise-grade managed services offer significantly better reliability, compliance posture, and total cost of ownership.
The fundamental principle: the cost of your data infrastructure should be proportional to the value of the data it produces. A well-selected scraping API, matched to your actual use case and volume, will outperform a custom-built scraper on every dimension that matters in production: reliability, maintainability, and time-to-data.
Review your requirements against the comparison tables in this guide, test on your actual target domains, and prioritize success rate and data quality over headline pricing.
For enterprise data collection requirements — including custom extraction schemas, compliance documentation, and AI training datasets — WebDataInsights provides end-to-end web data solutions designed for production scale.
Reliable Web Data Solutions
WebDataInsights provides clean, structured, and real-time web scraping solutions tailored to your business goals, helping automate data collection for eCommerce, market research, lead generation, and more.
Get in Touch